GitHub Copilotは、GitHubが提供するコード補完や生成などを主とするサービスです。GitHubアカウントがあれば無料で使用出来る他、月額10ドルからのProプランや組織向けのBusinessプラン(月額19ドル)などに加入するとより高品質なモデルを使用可能といった機能が追加されます。
このGitHub Copilotは従前、デフォルトでの学習のための入力データの再利用はプロンプト等を除いて行われていませんでしたが、2026年4月24日からはデフォルトで学習のための再利用を行うものとし、ユーザーがオプトアウト出来るようにすると発表が行われています。この記事ではその概要を簡単にまとめ、オプトアウトの手法に関しても記しておきます。
結論
- 4月24日より、Copilotへの入出力やコードスニペット等が学習に使用されるように
- ユーザーがオプトアウト可能
- 「業界慣行」に合わせた動きと主張
学習に使用されるデータ
3月3日、GitHubはそのコミュニティ上の投稿で、4月24日よりGitHub Copilotに入力されたデータなどに関してモデルの改善等のために再使用を行うことを公表しました。これはGitHub CopilotのFreeプラン・Proプラン・Pro+プランに対して行われるものであり、BusinessプランやEnterpriseプランは対象外であるとしています。記事内におけるFAQ内において、学習に使用されるデータの例として以下のものが挙げられています。
- ユーザーが受け入れまたは変更した出力
- モデルに示されたコードスニペットを含むGitHub Copilotに送信された入力
- ユーザーのカーソル位置に関するコードコンテキスト
- ユーザーが書いたコメントおよびドキュメント
- ファイル名、リポジトリ構造、およびナビゲーションパターン
- チャットやインライン提案を含むCopilot機能とのインタラクション
これはあくまで例示であり、これらが送信されない場合やこれら以外のデータが送信される可能性は否定されていません。また、これらの入出力はソースがプライベートリポジトリにあるかなどは関係なく、 Copilotに対して入出力が行われた場合収集されることが示されています 。有料のorganizationリポジトリやプライベートリポジトリから直接読み込むことは無いとされており、Copilotへの入力が行われた場合それが再活用されうると読み取れます。
注意が必要なのは、「ユーザーのカーソル位置に関するコードコンテキスト」も収集対象である点です。これは、チャット等への手動の入力がなくても、現在編集中のファイルや周囲のコードが自動的に送信・蓄積されうることを意味します。そのため、 「チャットを使わない」「機密コードをコピペしない」といった対策だけでは不十分 であり、プライバシーを確保するには下記の通り設定画面から明示的にオフにする必要があります。
また、収集されたデータはGitHubやMicrosoftとその関連会社等の従業員が閲覧可能であることが示されています。ただし単にGitHubにAIモデルやその他のサービスを提供する企業はデータを閲覧できるとはされていません。このようなデータにはAPIキー・パスワード・トークン・個人を特定できる情報を検出・削除するフィルターが実装されているとしていますが、フィルターは完璧であるものとはされていません。
オプトアウトの方法
先述の通り各ユーザーは学習への使用をオプトアウトすることが可能です。Copilotに関する設定より、「Privacy」セクションに存在する「Allow GitHub to use my data for AI model training」を「Disabled」にすると、学習が行われないものとされています。
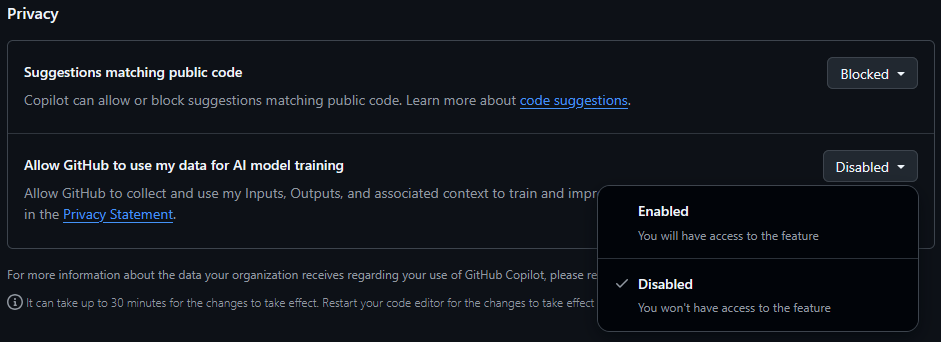
これは4月24日以前でも変更することが可能です。また以前「Enabling or disabling prompt and suggestion collection(プロンプトおよび提案の収集を有効化または無効化する)」設定において「Disabled」を選択した場合はその設定が引き継がれるとのことです。学習に使用されると問題になる可能性がある方は確認及び設定を行うことをおすすめします。
関連リンク
- Updates to GitHub Copilot interaction data usage policy - The GitHub Blog
- FAQ: Privacy Statement update on Copilot data use for model training (Free/Pro/Pro+)
- FAQ - GitHub Copilot Trust Center
- 4月24日から Copilot Free/Pro/Pro+ のインタラクションデータが AI モデルの学習に使用されるようになるので設定を確認した - DevelopersIO
最後に
公式ブログにおいて「This approach aligns with established industry practices and will improve model performance for all users.」としており、業界慣行に合わせた動きとしています。競合であるClaude CodeはClaudeサービス全体でAIモデルの向上のために学習をデフォルトで許可するようにしたり、Codexでは最初から学習を許可し、オプトアウト出来るようにしていたりと、同様の傾向を示しており、誇大なものとは言えないかもしれません。
ただ、既存のアプリケーションにおいてUX等を向上するためデータを使用することもあるかもしれませんが、AIモデルでの学習に使用されるとなると話が変わってきます。既存のサービス等におけるデータとは異なり、一旦モデルに含まれてしまえば後からオプトアウトすることが極めて困難であると言わざるを得ないからです。より正確に言えば、特定のモデルから特定のデータのみを後から確実に除外する方法は今のところモデルに含めないことしかないと言っても過言ではない、という感じでしょうか。
もちろん製品を改善するために実使用データが重要であることに異論はありません。しかしながら、これまでの慣行と同様の動きを無秩序に取ることの危うさは段違いだと考えています。今後とも、このような便利なツールとプライバシーや機密の関係性のバランスがどのように取られるべきかについて検討する必要があると思います。
